Using LLM to Generate Insightful Reports from Moonchain Data
This tutorial will guide you through the process of using a Large Language Model (LLM) to generate insightful reports based on Moonchain data. The integration of LLMs into data reporting workflows enables the transformation of raw data into coherent narratives, helping stakeholders grasp key insights quickly and efficiently.
We will cover the following steps:
- Collecting data from Moonchain
- Processing and formatting the collected data using Ragflow before sending it to a LLM for report generation
- Formatting and publishing the report to your desired platforms, such as Twitter.
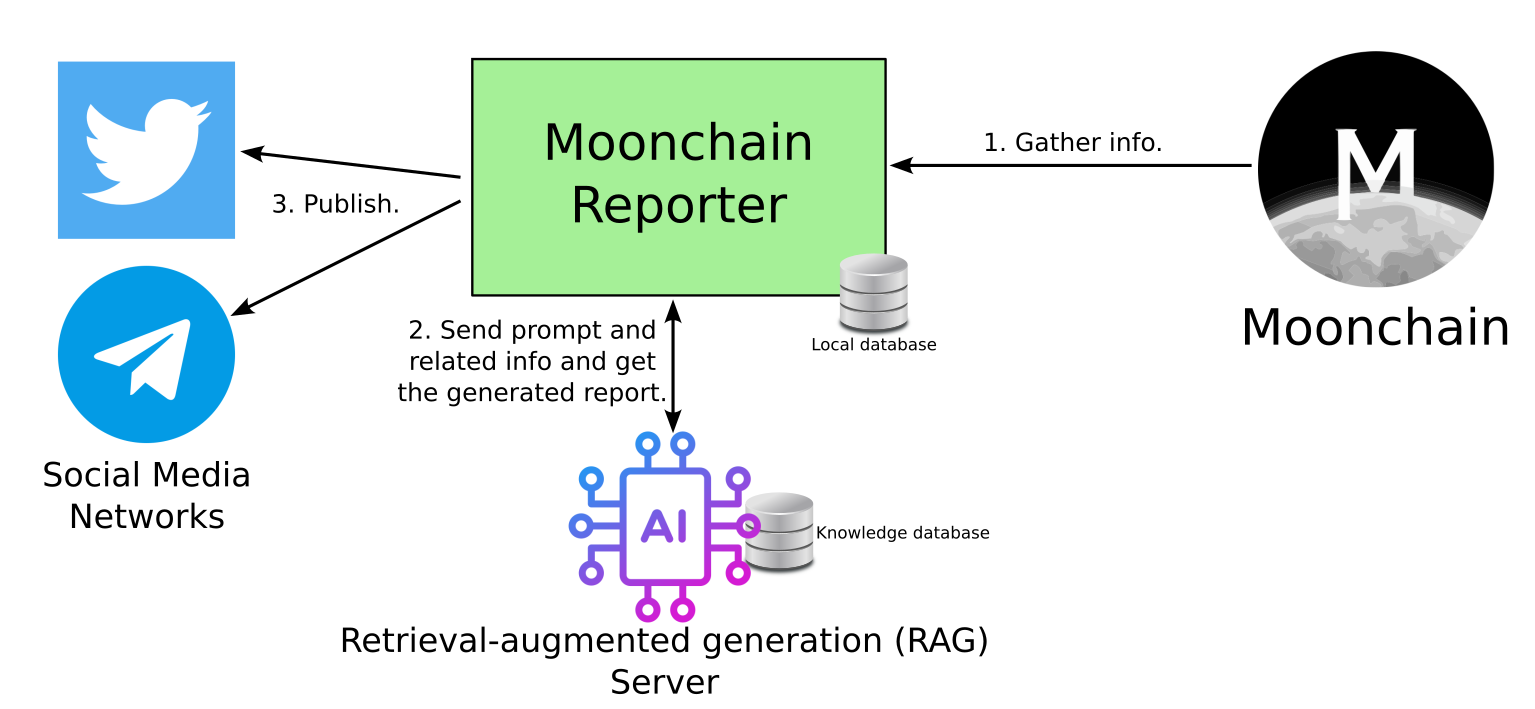
The above block diagram illustrates the workflow involved in generating insightful reports from Moonchain data using an LLM. It details the stages from data collection, through processing with Ragflow, to the final report generation and publishing.
By the end of this guide, you will be equipped to automate the reporting process, allowing for timely and insightful analysis of Moonchain’s performance metrics.
For those interested in the code implementation, you can find a complete example of the code and scripts at the following link: GitHub Repository - Moonchain-RagFlow-Twitter.
Let's get started!
Prerequisites
Before you start, make sure you have the following:
- Basic knowledge of Python programming
- Access to Moonchain data APIs
- An account with RagFlow
- Necessary libraries installed (e.g.,
requests,json,tweepy, etc.)
Getting Started
Setting Up the Virtual Environment
-
Open your terminal and navigate to the directory where you want to set up your project.
cd path/to/your/project-directory -
Create and activate a virtual environment. You can name it venv or any name of your choice.
python -m venv venvActivate the virtual environment:
On Windows:
venv\Scripts\Activate.ps1On macOS/Linux:
source venv/bin/activate
After activating, your terminal prompt should change to indicate that you are now working inside the virtual environment.
Step 1: Collecting Data from Moonchain
The primary purpose of the data collector script is to gather various performance metrics from the Moonchain API and store this data in a structured format (CSV files) for further processing. Here's a breakdown of its functionality:
Data Collection from Moonchain
Data Source
The script communicates with the Moonchain statistics API located at https://stats.moonchain.com/api/v1. This API provides various endpoints to fetch real-time data related to Moonchain’s operations, such as active accounts, transaction fees, and more.
It is designed to collect data for specific metrics over a defined period (e.g., the last two days). For each target date, it makes API requests to retrieve relevant statistics.
Daily Reports
For each day, the script generates a daily report by:
- Constructing a URL based on the selected metric and target date.
- Making an HTTP GET request to the API to fetch the data.
- Parsing the received JSON response to extract meaningful information.
Data Storage
The collected data is organized into CSV files. Each file is named based on the target date and contains columns such as:
- type: The category of data (e.g., active accounts, transaction fees).
- date: The date for which the data is collected.
- item: The specific metric name.
- value: The corresponding value for that metric.
Step 2: Processing and Formatting the Collected Data
Once the data has been collected from the Moonchain API, the next step is to process and format this data before sending it to a Large Language Model (LLM) for report generation. This step primarily involves combining the collected CSV files and preparing them for analysis. Here's how this process works:
Data Processing and Formatting
The script designed for this step performs several key tasks to ensure that the collected data is structured appropriately for further use:
-
Combining CSV Files: After data collection, the script consolidates all the CSV files generated from different days or metrics into a single comprehensive report. The script scans the specified output directory for any CSV files and reads the content of these files, preserving the header from the first file while appending the data from subsequent files. This ensures that all relevant data points are included in a unified format.
-
Generating a Prompt for the LLM: After combining and formatting the data, the script constructs a question or prompt that summarizes the information collected. This prompt is crafted to encourage the LLM to generate a coherent and insightful report based on the formatted data.
Sending Data to RagFlow
Once the data is processed and formatted, the script prepares to send the cleaned data along with the generated prompt to RagFlow. This involves:
-
API Requests to RagFlow: The script makes API requests to RagFlow, passing the formatted data and the prompt. RagFlow processes this information, chunking it appropriately for input into the selected Large Language Model (LLM).
-
Interfacing with the LLM: Once the data is sent to RagFlow, it forwards the chunks to the designated LLM. The LLM processes the input and generates a narrative or report based on the data received.
-
Receiving the Response: After the LLM has generated the report, it sends the information back to RagFlow, which then relays the final report back to your script. This report typically includes analyses, insights, and interpretations of the Moonchain metrics collected earlier.
Step 3: Publishing the Report to Twitter
Once the report has been generated by the LLM and sent back through RagFlow, the next step is to publish this report on Twitter. This step involves formatting the report appropriately and managing the constraints of Twitter's character limits. Here's how the Twitter posting process works:
Preparing the Report for Twitter
Reading the Generated Report & Splitting the Report into Tweets
The script begins by reading the generated report from a JSON file, which contains the insights and analyses produced by the LLM. Since Twitter has a character limit of 280 characters per tweet, the report text must be split into smaller segments.
- Line Splitting: The report is first split into lines to maintain logical breaks in the content.
- Word Handling: If any line exceeds the character limit, it is further broken down into individual words. The function checks the cumulative length of the words being added to the tweet. If adding another word would exceed the limit, the current content is saved as a tweet, and a new tweet starts with the current word.
This careful formatting ensures that each tweet remains within the character limit while preserving the meaning and coherence of the original report.
Posting the Tweets
The script utilizes the Tweepy library to interact with the Twitter API. It initializes a Twitter client with the necessary credentials (API key, API secret, access token, and access token secret). Once the client is set up, the script proceeds to post the tweets.
- Single Tweet Case: If the report is short enough to fit within a single tweet, it is posted directly.
- Tweet Thread: If the report is long and requires multiple tweets, the script manages a thread by posting the first tweet and then replying to it with the subsequent tweets.
Conclusion
In this tutorial, we explored the process of using a Large Language Model (LLM) to generate insightful reports from Moonchain data. By integrating data collection, processing, and report generation, we established a streamlined workflow that transforms raw performance metrics into coherent narratives.
We covered the following key steps:
-
Data Collection: We utilized the Moonchain API to gather vital performance metrics, such as active accounts, transaction fees, and more, storing this information in structured CSV files.
-
Data Processing and Formatting: Using RagFlow, we formatted the collected data and prepared it for submission to the LLM. This involved combining multiple CSV files into a single comprehensive report and generating a prompt to guide the LLM in report generation.
-
Report Generation: The LLM processed the formatted data, yielding insightful narratives and analyses that reflect the current performance of the Moonchain network.
-
Publishing to Twitter: Finally, we formatted the generated report into tweets, adhering to Twitter's character limits, and published it using the Tweepy library, allowing stakeholders to access and engage with the insights easily.
By automating this process, you can ensure timely and insightful analyses of Moonchain's performance metrics, aiding in informed decision-making and strategic planning.
For those interested in exploring the code implementation further, you can find a complete example of the code and scripts in the following GitHub repository: GitHub Repository - Moonchain-RagFlow-Twitter.
With these tools at your disposal, you are now equipped to harness the power of LLMs for reporting and analysis. Happy coding!